In the previous part, we’ve seen a few tricks which can help you split your TypeScript project into small packages. We were still missing a proper build system as well as a way to publish or deploy the packages. Which is what we will cover in this chapter.
Tips and tricks to structure multi-package TypeScript projects
I’ve been experimenting with ways to structure a complex TypeScript project lately while working on Vaultage and I have finally found a solution that provides proper isolation and consistency across packages.
Deal with nullables like they're not even here - Good coding practices in TypeScript.
Today we will take a look at a couple ways to improve your TypeScript code. By applying those techniques we will get code that is more readable, contains less bugs and is objectively higher-level without any downside. How cool is that ?
You should worry about Vary
We’ve all heard of XSS, SQLi and CSRF. And although they keep occurring all the time, any decent web framework nowadays has some mechanisms to avoid those. Now did you know CSRF had a little sister? It is so poorly known that it seems like it doesn’t even have its own name! Before explaining how it works, let’s see what it can do.
Some background
Meet Bob, a web dev who is in charge of writing a public facing API. Bob sets the Access-Control-Allow-Origin header to allow all origin domains. Indeed, Bob wants any website to be able to talk to his API. Now, being a thoughtful developer, Bob knows about CSRF and he builds an authentication mechanism that delivers access tokens. Without a proper access token, his API won’t talk!
Still following? Good, now you may be wondering what this API does. In fact this API allows different services to store and share credentials in the cloud. The way a service gets the credentials is by issuing a request like this one:1
2GET /vault/{account}/{service}
Authorization: Basic QWxhZGRpbjpPcGVuU2VzYW1l
Bob heard one day that Auth basic is unbreakable, therefore he is using this method to pass the API key and username.
But the backend is doing some crypto stuff and hence requesting the credentials is an expensive operation. Bob adds some Cache-Control information to tell the browser to cache the response for a little bit. This way Bob reduces the load on his server and improves the speed of apps consuming his API.
If the credentials check out, the API returns something like this:1
2
3
4
5
6
7
8200 OK
Access-Control-Allow-Origin: *
Access-Control-Allow-Headers: Authorization
Cache-Control: no-transform, max-age=600
Content-Length: 42
Content-Type: application/json
{"username":"Alice","password":"I4mab055"}
Everything works fine until one day, a client complains that her credentials got stolen…
Damn it Bob, again?!
You just got hit
Bob can check his server log for a while, he will never find anything. The attacker left no evidence behind because he never even had to talk to Bob’s API; Everything happened locally, in Alice’s browser. Alice received this stupid email a few days ago and couldn’t resist opening a link to a picture of a cat wearing a ninja-turtle mask.
While she was watching this picture, a piece of javascript issued an HTTP request in the background to Bob’s API and stole her credentials. But how did the malicious website get an API token in the first place you’ll ask? Well it didn’t. Because it never had to. A simple request without the Authorization header was enough to get the information.
Introducing: Vary
So there’s this thing in the HTTP spec that you may or may not have heard about. It’s called the Vary header. What it does is inform any cache about which request headers can cause the response to change. If the Vary header is omitted, then caches will disregard the request headers when deciding whether to serve the response from cache. In other words, no matter which headers were sent by the client the first time, the response will be cached and served back to every subsequent request until the response expires, regardless of the next request’s headers. Remember how Bob made the response cacheable for 10 minutes? This means that the attack is successful if it happens within 10 minutes of the original request.
To prevent this issue, the API should send the Vary header in its responses to inform caches that the response will be different for different values of the Authorization header. In our example we get:1
2
3
4
5
6
7
8
9200 OK
Access-Control-Allow-Origin: *
Access-Control-Allow-Headers: Authorization
Cache-Control: no-transform, max-age=600
Content-Length: 42
Content-Type: application/json
**Vary: Authorization**
{"username":"Alice","password":"I4mab055"}
Going beyond
So stealing information is fun but let’s see if we can use this flaw to do something better. Imagine a web page that allows a user to set a message of the day, stores it in the cookies and displays it whenever the user visits the page for the rest of the day. The page is cached and can be fetched cross-domain just like in the previous example and it doesn’t have Vary: Cookie. If a user visits my website, I could issue a request to the greetings page with a custom Cookie. If I manage to perform this request when the page is not in cache yet, then the browser will fetch the page with my custom cookie and store it. Yes, we just found ourselves a cache-poisoning vulnerability. Now guess what happens next if this page allows the greeting message to contain javascript?
Depending on the cache headers, it may even be possible that the response gets cached on a server sitting between the victim and the origin. In this situation the attacker can read the victim’s data without even running code in her browser! All that is required is a hit on the cache server.
Wrapping up
I wish this article will at least allow a few people to get awareness about the dangers associated with Cache-Control and the Vary header. This vulnerability is similar to CSRF in that it allows cross domain requests to do some damage. It is harder to exploit and does not allow to reach the server. This however makes it impossible to detect attacks while still allowing some information leakage and defacing. In the case of cache poisoning, it opens up the attacks surface to find other vulnerabilities such as XSS or even SQL injections.
The fact that this vulnerability lies in the shadow of the big names like XSS makes it more likely to be looked over. In fact it has occurred before and I bet there are exploitable scenarios in the wild like those discussed above. So be careful next time you build an API and take some time to review your response headers. It can sometimes be trickier than you’d think figuring out which headers make the response change!
You may want to try out this quick and dirty proof of concept to see this flaw in action.
GitHub's "merge pull request" is wrong
This is the story of Bob. Bob is working on some cool project on github. He’s written tests and runs them continuously on travis. Bob asks his contributors to write tests for new features they introduce. Using GitHub’s pull requests, he can make sure no bugs are introduced by looking for the green tick next to the commit number. If you look at the commit tree in Bob’s repository, you’ll probably find something like this.
Bob states in his contribution guide that people can fork master to work on new features. He guarantees that master’s tests always pass and therefore, individual contributors don’t need to worry that much about errors made by other developers.
If you’re familiar with github then you are probably familiar with this workflow and you’ll think that it’s perfectly reasonable.
But you’ll be wrong. Bob got overly enthusiastic about github’s UI and will soon discover that he’s been wrong all this time.
A catastrophic scenario
Say two contributors, Alice and Charlie, are writing code for Bob’s project in their respective branches. In this project, we find the following code for operating Bob’s car:1
2
3
4
5
6
7
8
private void doSomething(String action) {
switch (action) {
case "OPEN_DOOR":
open_door();
break;
}
}
Now Alice thinks it would be better if Bob used an enum instead of a string. She changes the function to the following and opens a pull request on Bob’s project.1
2
3
4
5
6
7
8
private void doSomething(Action action) {
switch (action) {
case Action.OPEN_DOOR:
open_door();
break;
}
}
Bob opens his project page and sees a pull request. He thinks Alice’s modification makes sense and, since all tests passed, he clicks on the green button.
[caption id=”attachment_221” align=”alignnone” width=”776”]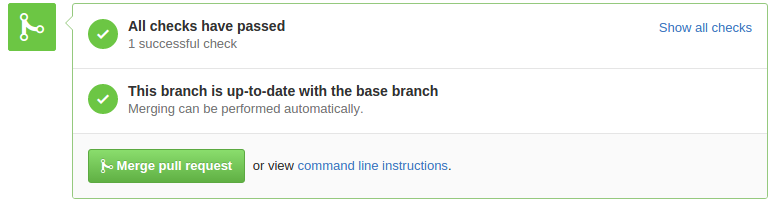 The button of doom[/caption]
The button of doom[/caption]
Meanwhile, Charlie thinks Bob will need to close his car’s door at some point. Charlie adds a new case to the switch:
1 |
|
The next day, Bob opens his project on GitHub and sees Charlie’s pull request. All tests passed, no merge conflict, that’s a clear LGTM and Bob merges the code.
A few days later, Bob receives complaints from multiple developers, they forked master and it doesn’t build!
What could go wrong?
The problem lies in a common misunderstanding of the following assumptions.
- Different PRs must be completely independent
- No merge conflicts ≠ No conflicts
If you accept one of these to be violated, then expect your main branch to fail tests!
If we speak in terms of diff, then Alice’s diff is the following:1
2
3
4
5
6
7
8
- private void doSomething(String action) {
+ private void doSomething(Action action) {
switch (action) {
- case "OPEN_DOOR":
+ case Action.OPEN_DOOR:
open_door();
...
While Bob’s diff looks like this:1
2
3
4
5
6
7
8
...
break;
+ case "CLOSE_DOOR":
+ close_door();
+ break;
}
...
Put together we get1
2
3
4
5
6
7
8
9
10
11
12
- private void doSomething(String action) {
+ private void doSomething(Action action) {
switch (action) {
- case "OPEN_DOOR":
+ case Action.OPEN_DOOR:
open_door();
break;
+ case "CLOSE_DOOR":
+ close_door();
+ break;
...
This diff does not cause a merge conflict but it is actually in conflict!
–no-ff and the button of doom
The flaw resides in that big old “merge pull request” button. While the green checks above the button and its fat style make pressing it a rewarding thing, it hides the real danger behind it: a blind merge!
The above example looks like this in terms of commit history:1
2
3
4
5
6
7
8
+-PR_Charlie-+
/ \
+--PR_Alice--+ \
/ \ \
---+----------------x---x
|
master
All changes introduced by Alice and Charlie on their respective PRs have been tested, but the merge commits (marked ‘x’ above) were not! This is called a “non fast-forward” merge (–no-ff in git) and is basically like committing directly on master.
The right way to do it
Assuming you are like Bob and want your main branch to always pass tests, then here is the right way to do this: Merge master into the PR fisrt, and merge only when fast forward. It would look like that:
1 |
|
The end result is exactly the same as before EXCEPT that master was merged into the PR first, and this (if properly pushed to github) allows the automated tools to test the last commit. This ensures that master builds because master will always be on a commit that has been tested before.
Many beginner (and even advanced) programmers get fooled into thinking that merging a green pull request cannot harm. In an ideal world, clicking the green button would: merge master into the branch, wait for the tests to pass, and on success, fast-forward master to the merge commit. But unfortunately I don’t think this is coming anytime soon. In the meantime, think about it twice before you press the button of doom. And when in doubt, run the merge sequence manually in the right order. This may save you a few hours of debugging.
View all posts